Slide uploaded on 01/Jul/2020
Updated on 01/May/2020
There are other two areas where it is possible to reduce the AWS cost:
Considering migrate from Classic Load Balancer to Application Load Balancer (technical debt):
ALBis about10%cheaper thanELB(AWS Load Balancing pricing)- Convenient to perform Canary Depoyments in CI / CD
Using AWS Savings Plans: please refer to my article about AWS Savings Plans Overview
Rather than write a big, manual-style cost optimization guide, I’d like to share a few pits I’ve encountered during the process.
Tools
Common tools for AWS cost optimization are as follows:
- AWS Cost Explorer
- Cost Reports in S3
- AWS Trusted Advisor - Cost Optimization
Strategies
Based on AWS Cost Optimization Best Practice, the main measures are probably the following aspects:
- Right Sizing: Use a more appropriate (convenient) Instance Type / Family (for EC2 / RDS)
- Price models: leverage Reserved Instances (RI) and Spot Instances (SI)
- Delete / Stop unused resources: e.g. EBS Volume / Snapshot, EC2 / RDS / EIP / ELB, etc.
- Storage Tier / Backup Policy: Move cold data to cheaper storage tiers like Glacier; Review EBS Snapshot / RDS backup policy
- Right Tagging: Enforce allocation tagging, while improving Tag coverage and accuracy
- Scheduling On / Off times: Review existing Auto Scaling policies; Stop instances used in Dev and Prod when not in use and start them again when needed
Corresponding to the specific situation of the company, mainly want to talk about 3 and 4 mentioned above.
About Backup
AWS Backup
At first, the company used Lambda Function (Python script) to handle EBS / RDS backup. Later, because of the release of AWS Backup Service, it was decided to migrate backup management to AWS Backup.
However, for Database backup, because AWS Backup Service does not support Aurora, so we still need to keep the original Lambda.
AWS Backup currently supports all Amazon RDS database engines except Amazon Aurora.
For AWS Backup, it can support multiple AWS Services / Resources, such as:
Amazon EFS
DynamoDB
Amazon EBS Snapshots
Amazon RDS DB Instances
AWS Storage Gateway
Unfortunately, AWS Backup does not support the Wildcard (*) to match resources.
For example:
Internally we use Terraform as IaC (Infrastructure as code) to automate the management of resources on AWS.
Examples of corresponding AWS Backup codes:
1 | resources = [ |
Therefore, the corresponding Backup solution is:
Either specify the specific
Resource ID(useresourcesto specify, but cannot support something likearn:aws:rds:${region}:${account_id}:db:*)Either use
Tagsto mark the resources to be backed up by AWS Backup Service
Of course, the former is certainly not realistic, which means:
The feature of AWS Backup determins (well, I believe this is not a bug), in fact you can only use Tags, and need to set Resources to empty [] (by default it’s for all Resource types supported by AWS Backup). Thus laying a hidden danger.
Note: The relationship between
TagsisOR, so as long as oneTagget matched, AWS Backup will back it up.
The foreplay is over, and the pit is coming!
At the beginning of March, it was found that the AWS bill was obviously abnormal. After analysis, it was found that the cost of EBS snapshots increased too fast.
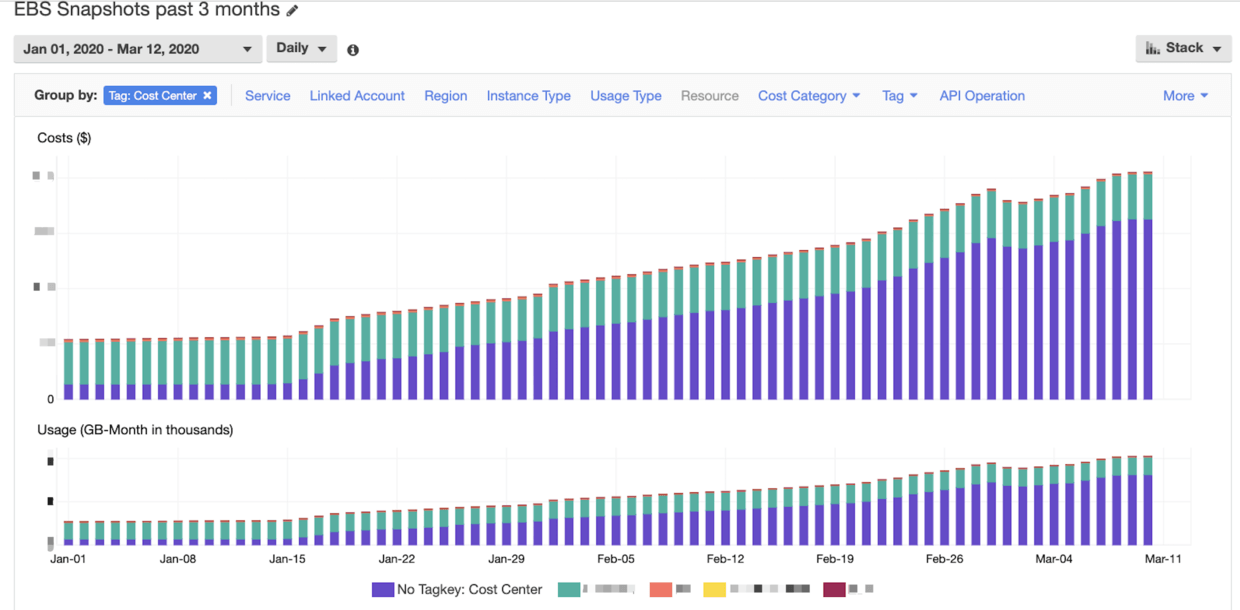
As you can see in the chart, it started to grow slowly from around January 15th, so what happened at this time?
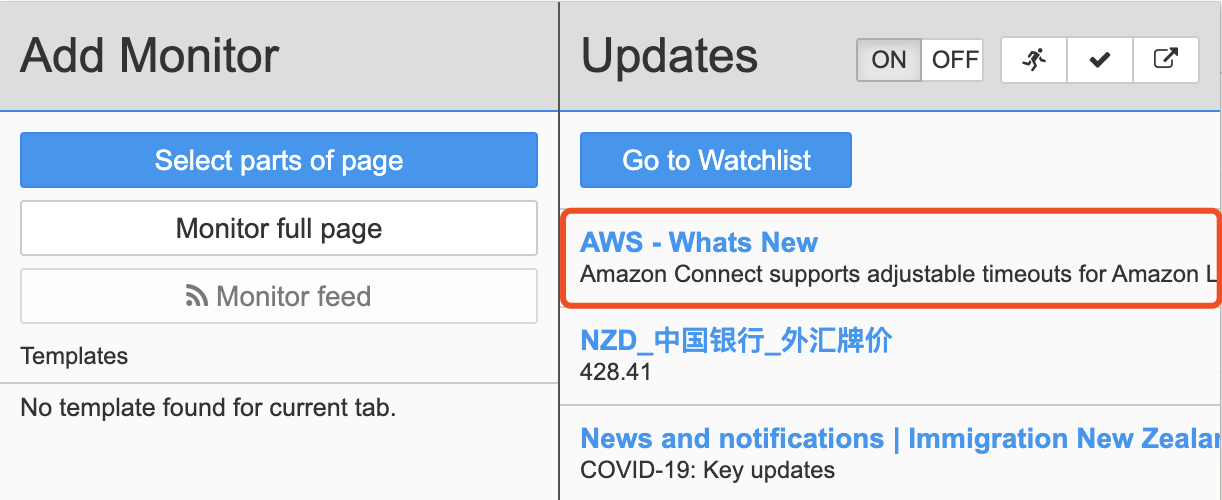
The internal search was fruitless. After googling, I found a suspicious What’s New message from AWS official website.
Hmmmmmm, perfectly matched…
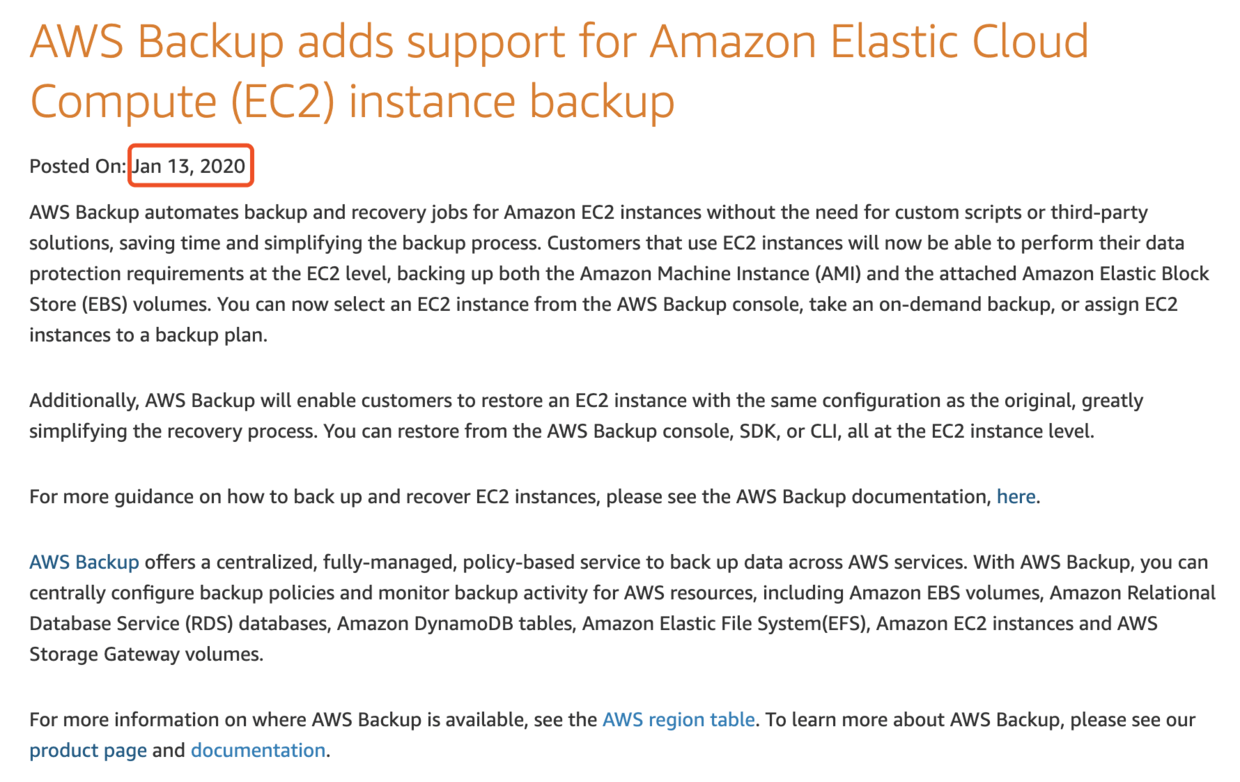
Okay! Looks like AWS help me to back up all the EC2 instances by default… Thank you!
According to the documentation, for AWS Backup, in addition to EBS Snapshot itself, it will also make an AMI copy for each EC2 instance, so that’s why there are a lot of AMIs.
When backing up an Amazon EC2 instance, AWS Backup takes a snapshot of the root Amazon EBS storage volume, the launch configurations, and all associated EBS volumes. AWS Backup stores certain configuration parameters of the EC2 instance, including instance type, security groups, Amazon VPC, monitoring configuration, and tags. The backup data is stored as an Amazon EBS volume-backed AMI (Amazon Machine Image).
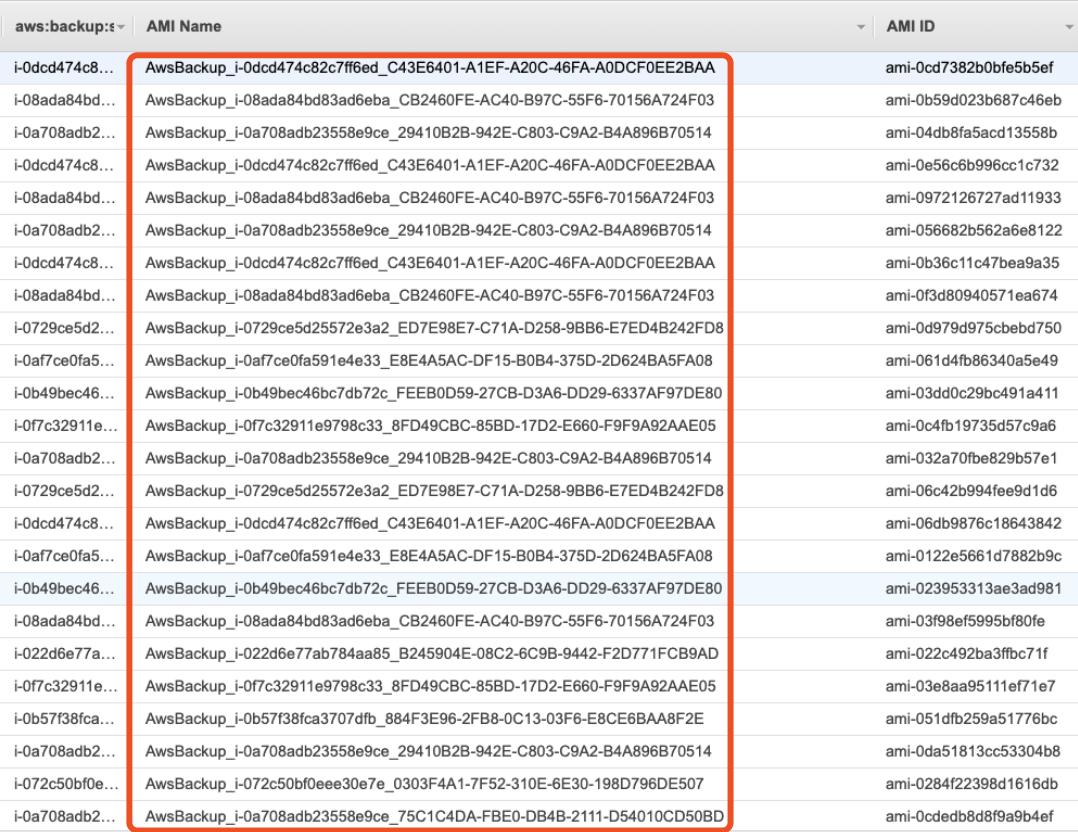
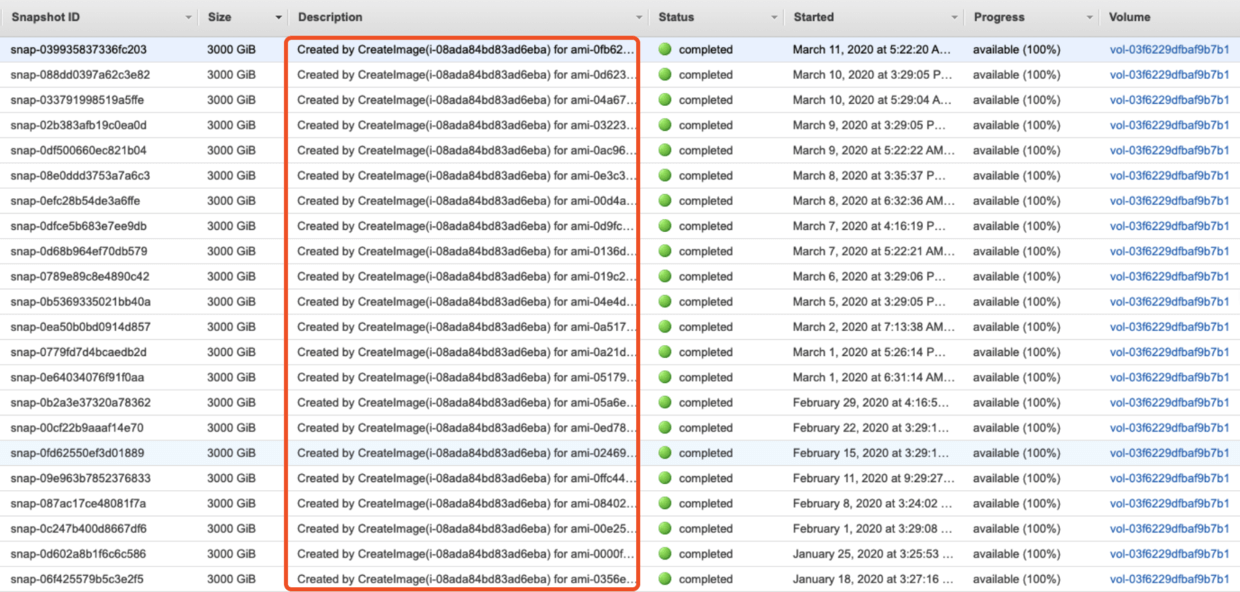
According to the previous AWS Backup execution logic, for all supported types (including newly supported EC2 on January 13), as long as the tag is matched, the backup will be performed.
So, for EC2 AMI / EBS snapshot, how Tags are added by default?
Checked the Terraform code:
1 | resource "aws_autoscaling_group" "main" { |
Since propagate_at_launch = true is used, the tags of ASG will be copied when EC2 launches.
In addition, after EC2 is started, the initialization script will be run through Puppet to copy the ASG / EC2 tags to EBS Volumes. Code example as follows:
1 | # Retrieve the tags attached to the instance if no auto-scaling group exists. |
So the current Tags replication chain:
ASG-> EC2-> EBS Volume
As for the solution, just to differentiate Tags between EC2 and EBS, and delete the tags that will be matched by AWS Backup (here is MakeSnapshot*), to achieve the purpose of “Backing up EBS only, not EC2 instance”:
1 | if [ "$asg" != "" ]; then |
The effect after cleaning:
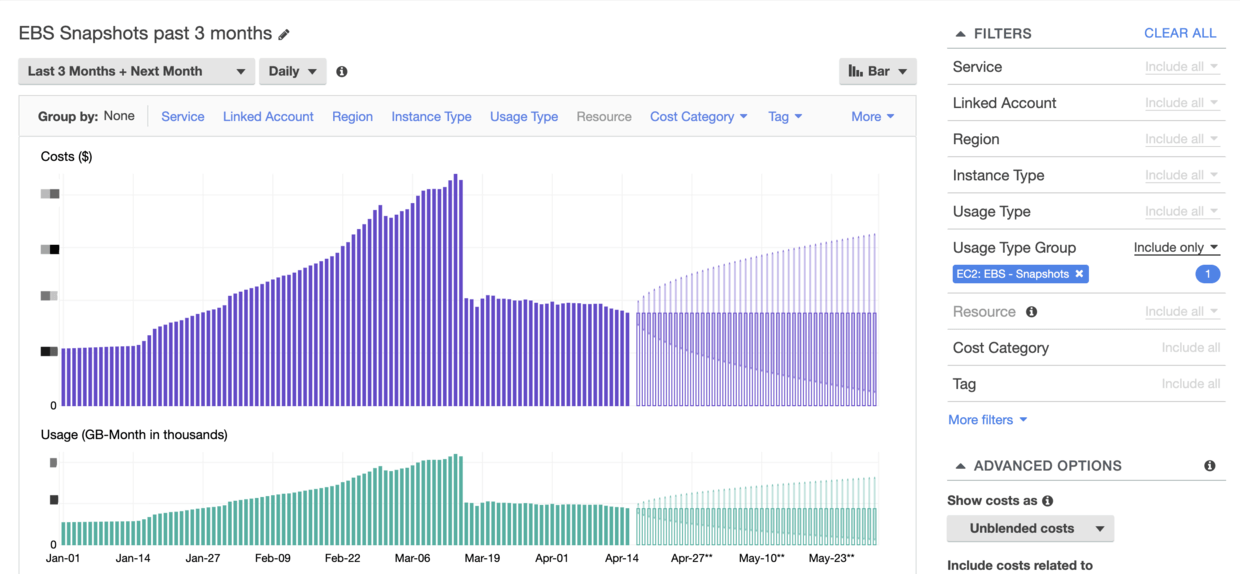
After this battle, I completely felt the fear of being dominated by AWS Bills :-(
You can’t plant heels in the same place, so just add monitoring for news from AWS :-)
About DB storage
RDS backup storage excess free allocation
Potential increase to your Amazon Aurora bill [AWS Account: XXXXXXXXX]
Starting March 1, 2020, we will start charging for backup storage in excess of the free allocation. There will not be be any back-dated or retroactive charges for use of Aurora backups before March 1, 2020.
You can review your current backup retention policy and snapshots on the RDS Management Console. You can lower your monthly bill by reducing your backup retention window or by deleting unnecessary snapshots.
Usually, in our SRE team who is on duty will also pay attention to daily BAU such as consultation / email etc., but on that day, the unlucky guy was too busy to ignore the AWS email when received it, and therefore didn’t create a JIRA ticket, but (the interesting thing is) everyone in the team missed it as well, which is pretty strange.
As a result, we didn’t realize until reviewing the AWS Cost, and the price is not cheap actually:
$ 0.095 per additional GB-month of backup storage exceeding free allocation
Currently the company’s default setting of backup_retention_period for RDS is30 days, and this time, of course, we need to reduce it.
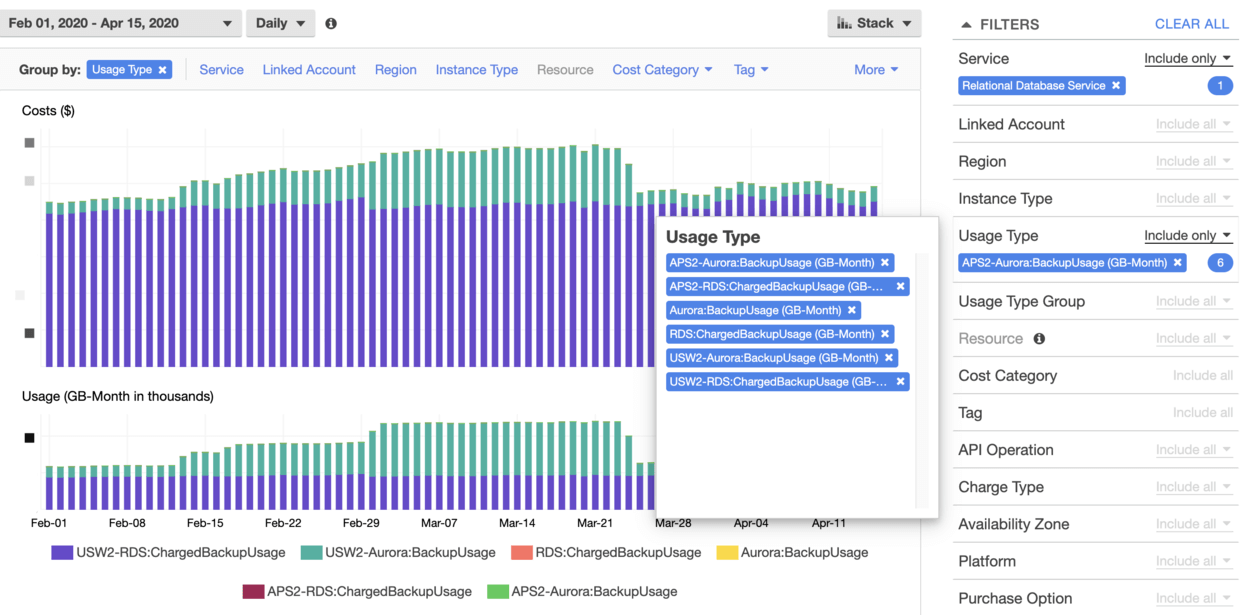
The effect is as follows, better than nothing:
Can see a 70% drop for USW2-Aurora:BackupUsage after reducing retention period
About Data Transfer
One of the more interesting things during this period is that, I found there is something called EC2-others in the AWS Cost Report. Here is the official statement:
The EC2-Other category includes multiple service-related usage types, tracking costs associated:
- Amazon EBS volumes and snapshots
- Elastic IP addresses
- NAT gateways
- Data transfer
Through ithe Billing Report, I found that the following is the culprit:
![]()
How to locate
Using Cost Explorer, we can locate the specific item with the following settings:
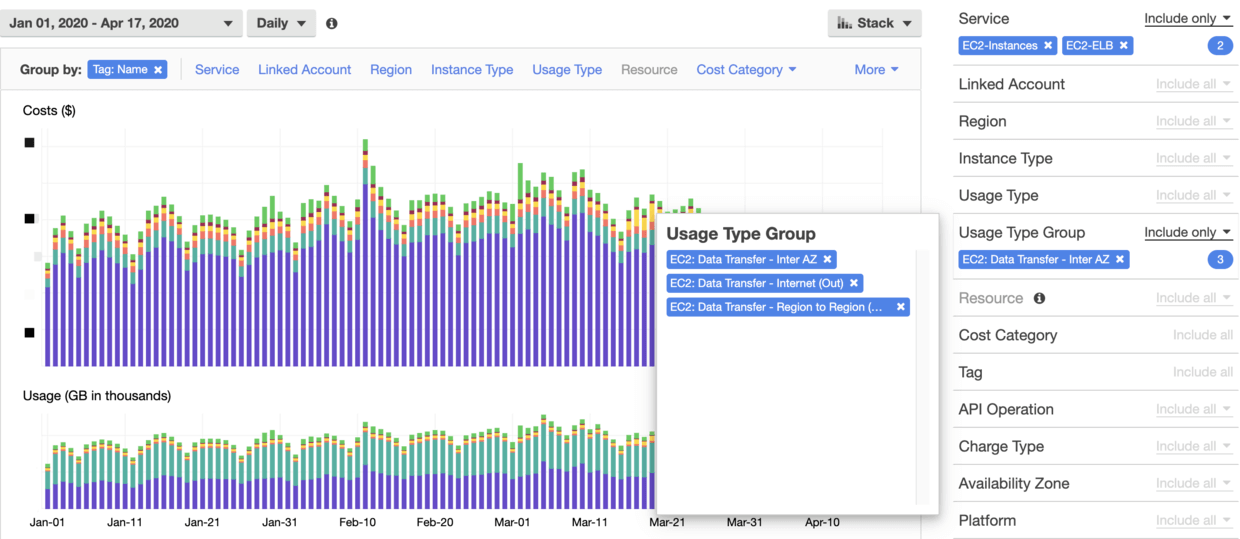
Finally, the major part of Data Transfer is located, which comes from a (business) Load Balancer, followed by the Network Load Balancer (NLB) that for Logging.
How to reduce data transmission costs
A picture is worth a thousand words:
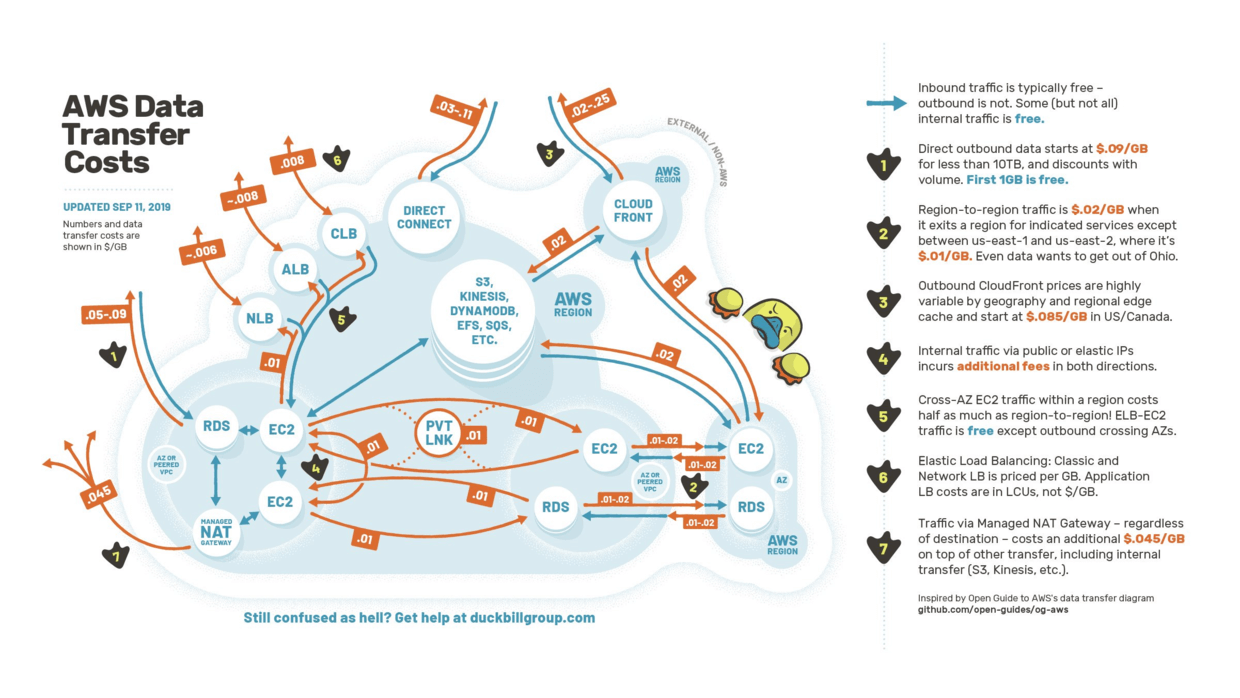
There’re some general strategies, such as:
Limit data transfer to the same AZ as much as possible, or between AZs or the same Region.
Use Private IP whenever possible.
For example:
EC2 that needs to communicate in a development or test environment should be in the same Availability Zone (AZ) to avoid data transfer costs.
EC2 can use CloudFront (CDN) if it needs to transfer data such as pictures / videos to Public.
For resources in different Regions or multiple Accounts, can use VPC Peering or VPC Sharing to further reduce transfer costs.
In reality, a multi-pronged strategy has been adopted.
After locating certain LB problems, the method of “directly reducing the transmitted data” was adopted, e.g.:
Turn off
log_subrequestconfig inOpenResty(Nginx)disables logging of subrequests into access_log
Add filter strategy in
Logstashto discard some useless dataIn
Rsyslog, enable the compression mode for omfwd module. Generally, a medium compression level should be fine, for example,ZipLevelcan be set to3-5, andcompression.modecan be set tosingle, which means each message will be evaluated and only the larger message will be compressed. And here in order to save costs, a more aggressive strategy is adopted, which will introduce delay but it’s acceptable.1
2
3ZipLevel = "9"
compression.mode = "stream: always"
compression.stream.flushOnTXEnd = "off"In addition, can also consider adjusting the
index.codecconfiguration ofElasticSearch, usingbest_compressionto replace the default compression algorithmLZ4to achieve a higher compression ratio, in order to reduce data transfer across AZ (such asshard allocation)
Well, for the time being, it is predicted that Cost Optimization will be a protracted battle, especially in the current environment of global economic impact.
Therefore, we really need to pay more attention to cost optimization, not only from the beginning of architecture / solution design, development and daily maintenance, but also need to create a lean cost-centric culture.
References
AWS Cost Management
Cost Optimization-AWS Well-Architected Framework
AWS Backup: working-with-other-services
AWS Load Balancing pricing

